Статья содержит обзор алгоритма гиперболической кластеризации, его реализации в программе TopSite и работы с ним в разных режимах. Вводная статья о кластеризации находится здесь.
Алгоритм гиперболической кластеризации запросов
В данное время существуют алгоритмы группировки ключевых слов (кластеризации), использующие поисковую выдачу (кластеризация по выдаче). Они работают по принципу подсчёта количества совпавших URL-адресов в поисковой выдаче по исследуемым запросам. Обычно используется ТОП-10 результатов, но может быть и больше.
Очевидным недостатком таких алгоритмов является то, что они подсчитывают число совпадений URL-адресов при помощи простого суммирования, что не совсем корректно. Вес первого места в поиске и сложность попадания на него несравнимо выше нежели, скажем, попадание на 10 место. И тем более выше, чем попадание на 100 или 1000 место. Согласитесь, на 100 место может попасть практически любой сайт, даже новичок. К тому же, если по заданному запросу мало документов, то уже начиная с 10-го места можно часто видеть совершенно нерелевантные документы, в которых просто совпало несколько искомых слов.
Ситуация усугубляется тем, что ТОП-10 бывает недостаточно для качественной кластеризации т.к. часто по похожим запросам в ТОП-10 можно увидеть одни и те же сайты. Иногда даже один сайт может занимать три, пять и даже семь(!) первых мест. А увеличение числа используемых результатов может привести к тому, что качество снизится уже по другой причине: из-за большого числа малорелевантных результатов "в хвосте". А так как всем совпадениям сопоставляется один и тот же вес, то правильные совпадения теряются среди случайных. И кластеризация превращается в рандом.
Что предлагается?
Очевидным решением является уменьшающийся вес совпадения URL-адресов от 1-го места к 30-му. ТОП-30 был выбран потому, что ТОП-10 мало, а ТОП-50 — много). На самом деле, до ТОП-30 чаще всего и находится большинство релевантных результатов. По ним и будем кластеризовать.
Вообще, понятие кластера весьма условно. В поисковой выдаче нет кластеров, как таковых. И то, что какой-то алгоритм определяет пару поисковых запросов как запросы из одного кластера, вовсе не означает, что так будет всегда и вы должны строго этого придерживаться. При появлении новых товаров, понятий, названий, тенденций и пр. кластеры могут разбиваться (чаще всего) или сливаться. Однако, кластеризация позволяет нам достигать некоторых целей:
- Очистка семантического ядра от неподходящих ключевых слов;
- Группировка ключевых слов для создания структуры сайта или контекстных объявлений;
- Более полное понимание намерений пользователей по неоднозначным поисковым запросам;
- Выделение региональных, коммерческих и других специфических типов поисковых запросов;
- Объединение в одну группу поисковых запросов, сильно отличающихся по написанию, но идентичных по содержанию или намерению пользователя;
- Оценка необходимости разделения похожих поисковых запросов на разные группы для раздельного продвижения из-за высокой конкуренции;
- Другие задачи, решение которых требует объединения ключевых слов в группы, подразумевающие одно и то же намерение пользователя, осуществляющего поиск в поисковой системе по этим ключевым словам.
Известные источники
При возникновении идеи уменьшающегося веса возник вопрос: насколько быстро он должен уменьшаться и как это должно выглядеть: равномерное уменьшение, параболическое или гиперболическое? Первые два варианта были отсеяны практически сразу после получения результатов первых тестов. Прямая не подходит совершенно, а парабола имеет не ту кривизну. Даже если использовать только левую часть параболы с ветвями вверх от точки минимума, то её всё равно не удаётся подстроить для получения адекватных результатов на всём спектре поисковых запросов.
В пользу гиперболы говорит и здравый смысл, и исследования CTR поисковой выдачи (надо сказать, довольно скудные). Одно из последних найденных расположено здесь: Google Organic CTR History и постоянно обновляется. Отличием гиперболы (её положительной ветви, речь идёт об уравнении y = 1/x) является её замедляющееся убывание с асимптотой в нуле. По ссылке выше вы можете увидеть как раз нечто, похожее на гиперболу. Интересно, что 75-80% переходов приходятся на ТОП-10. На все остальные приходится лишь около 20%. Релевантность, вероятно, падает примерно так же.
Стоит сказать, что релевантность хвоста при большой конкуренции обычно увеличивается, но в ТОП-10 могут попасть далеко не все. Поэтому, по мере увеличения конкуренции, поисковая система просто вынуждена чем-то жертвовать. По наблюдениям, в первую очередь она жертвует шириной спектра. Если при низкой конкуренции поисковик может позволить себе подмешать в ответ и какие-то дополнительные результаты, которые не совсем точно подходят под конкретно заданный запрос (просто потому, что найденных документов недостаточное количество), то по мере увеличения конкуренции таких подмешиваний становится всё меньше и ответ на запрос становится всё более конкретным или точным. На самом деле, эта примесь никуда не девается. Она просто отодвигается всё дальше от ТОПа.
Однако, поведенческие факторы и развитая система статистики современных поисковых систем, позволяет им находить такие запросы пользователей, которые могут быть написаны совершенно по разному, но при этом иметь один и тот же смысл. Такие результаты могут добавляться в ответ на запрос даже если сам запрос не содержит конкретно этих слов и даже при высокой конкуренции. В то же время, похожие запросы могут намеренно разделяться в зависимости от региона или типа запроса: коммерческий или некоммерческий. Причём "коммерческость" запроса может изменяться с течением времени. Результатом всего этого является разная выдача. А конкретно: различные URL адреса в результатах поиска. И именно поэтому сравнивая адреса в поисковой выдаче, мы можем различить разные типы запросов и распределить их по разным кластерам.
Продолжая эксперименты
Для экспериментов было выбрано несколько групп запросов: от маленьких — в 150 ключевых слов, до больших — 110 000 ключей. Они так же различались по степени разнородности содержащихся в них запросов. Большое спасибо сервису xmlproxy.ru за предоставленные лимиты запросов к Яндексу. Без них провести такие объёмные тесты было бы невозможно. Параметры гиперболы, похожие чем-то на вышеуказанные данные по CTR поисковой выдачи, имеют довольно неплохие результаты по качеству кластеризации. Однако, по степени кривизны рабочая гипербола всё же отличается от кривой CTR т.к. последняя слишком резко убывает в начале, что сказывается на качестве кластеризации, придавая слишком много значения первым результатам и практически не учитывая остальные. Наилучшие (на данный момент) результаты получены с использованием следующей кривой:
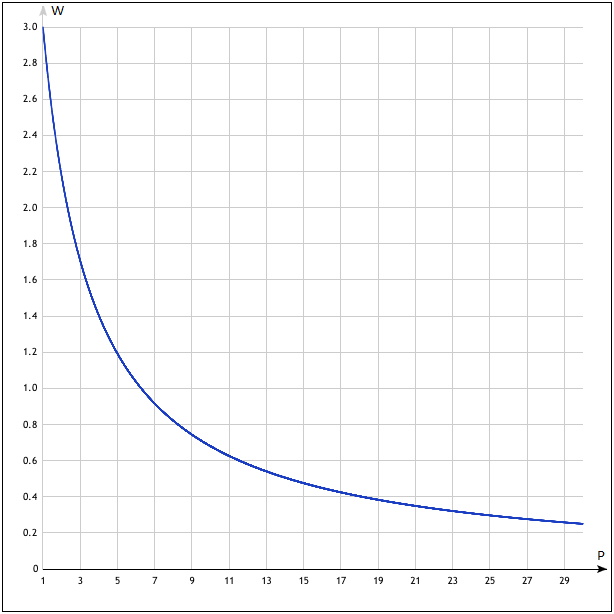
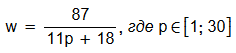
Масштаб вертикальной шкалы на представленном выше графике в 10 раз больше масштаба горизонтальной шкалы. Поэтому гипербола может показаться довольно круто уходящей вверх, но это не так. К тому же, при подсчёте итогового значения дельты, значения ещё больше сглаживаются, используя перемножение весов с последующим извлечением квадратного корня:
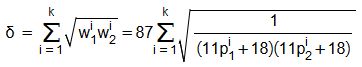
В итоге, комбинации из двух URL образуют довольно пологую поверхность падающего листа (приподнятого за уголок):
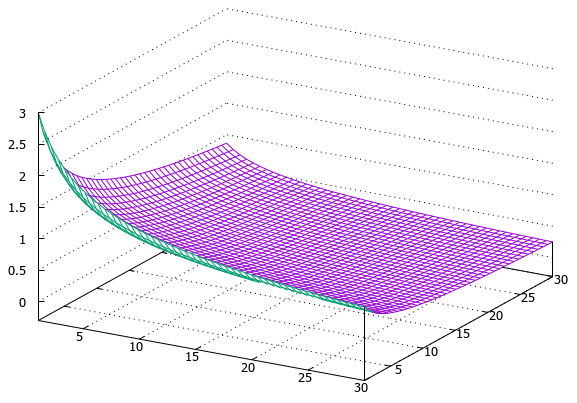
Более подробное описание алгоритма вы можете посмотреть здесь. Здесь же мы рассмотрим реализацию алгоритма в программе TopSite.
Реализация алгоритма гиперболической кластеризации в программе TopSite
Алгоритм гиперболической кластеризации в программе TopSite реализован как дополнительная операция при проверке позиций. Для того чтобы активировать кластеризацию, нужно открыть настройки программы и на вкладке «Кластеризация» отметить первую галочку:
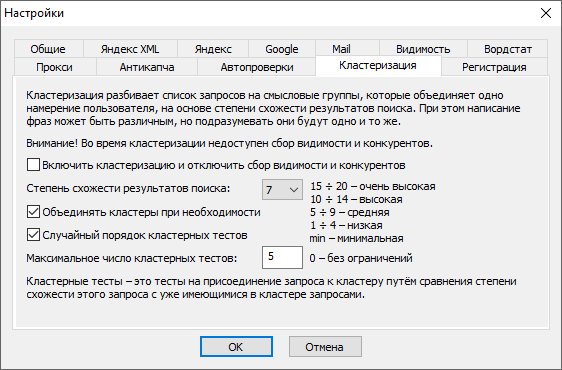
Для быстрого включения и отключения режима кластеризации имеется специальная кнопка, которая дублирует галочку в настройках и при включенной кластеризации подсвечивается красным цветом:

Из-за того, что для кластеризации обычно используется много ключевых слов, то при включении этого режима намеренно отключается сбор видимости и конкурентов как очень ресурсозатратные операции.
Кластеризация в TopSite может производиться по выдаче поисковых систем Яндекс и Google. Сбор с поисковика Mail в группе, где проводится кластеризация, лучше отключить. В этом случае, при проведении кластеризации, домен сайта указывать необязательно. Но если сайт уже существует, то его домен лучше указать для того чтобы собрать релевантные страницы. На производительность алгоритма это никак не повлияет.
Программа TopSite также позволяет сделать перекластеризацию, если данные уже были собраны. Эти данные сохраняются до выключения программы. Перекластеризация реализована отдельным модулем, не требующим доступа к сети и запускается через пункт меню кнопки запуска. При этом неважно, активен ли режим кластеризации. В остальном, перекластеризация работает с учётом тех же настроек, что и режим кластеризации.
Настройки кластеризатора
Вернёмся к настройкам кластеризации. Движок кластеризатора устроен так, что выставленные настройки важно задать до начала кластеризации (кроме включения самого режима кластеризации, который должен быть активен в процессе работы). Настройки кластеризации сохраняются в группе при старте кластеризации или перекластеризации и больше уже не изменяются вплоть до завершения работы с группой. Если вам нужно запустить сразу две группы запросов на кластеризацию с разными настройками, то сначала следует запустить одну, а затем, поменяв настройки, запустить другую группу. Каждая группа будет обработана в соответствии с настройками, которые были заданы во время запуска. Речь идёт только об этих настройках:
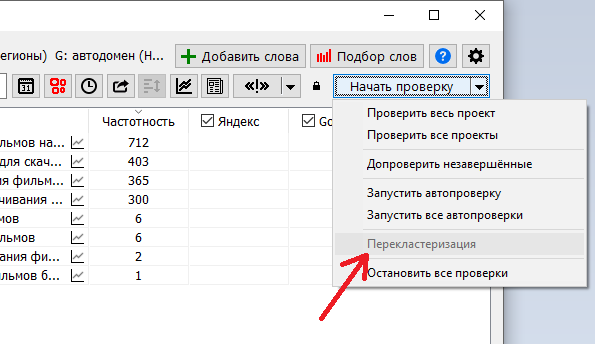
Степень схожести результатов поиска — это то самое пороговое значение δ0, использующееся в алгоритме. Рекомендуется подбирать его эмпирическим путём.
Объединять кластеры при необходимости — настройка, позволяющая отключить объединение кластеров в некоторых случаях (режимы будут описаны чудь ниже). Рекомендуется эту опцию держать включенной.
Случайный порядок кластерных тестов — это порядок (последовательный или в случайном порядке), в котором будут перебираться запросы, уже имеющиеся в кластере, при сравнении нового запроса с ними на предмет добавления нового запроса в этот кластер.
Максимальное число кластерных тестов — число, определяющее максимальное количество запросов, которые перебираются в больших кластерах чтобы несколько ускорить работу алгоритма и сделать отбор более жёским. При задании значения 0 — перебираться будут все запросы кластера в порядке, определяемом предыдущей настройкой.
Режимы работы алгоритма
Кластеризатор программы TopSite можно использовать в различных режимах, изменяя описанные выше настройки. К примеру, выставив «Максимальное число кластерных тестов» в значение 1 и отключив «Случайный порядок кластерных тестов», вы можете добиться того, что все запросы кластера будут сравниваться с одним (первым добавленным) ключевым словом (точнее, с выдачей по нему). Увеличивая это число, вы можете регулировать глубину сравнения, если это необходимо.
Вы также можете отключить в настройках программы на вкладке «Общие» опцию «Проверять запросы внутри группы в случайном порядке» и, отсортировав ключевые слова в группе по убыванию частотности, провести кластеризацию запросов, используя в качестве опорных ключевых слов запросы с большей частотностью. В этом режиме объединение кластеров лучше отключить и запрос будет добавляться в первый подходящий кластер без проверки остальных на объединение с ним.
Начальное дробление группы
Иногда, при работе с большим числом ключевых слов, бывает необходимо сначала разбить группу на более мелкие и уже потом работать с каждой группой отдельно. Для этого можно использовать режим работы «Начальное дробление» (название условное). Он позволяет раздробить большую группу запросов на кластеры максимальной ширины без потери качества последующей кластеризации и одновременно собрать данные. Дальнейшая обработка производится при помощи перекластеризации.
Чтобы сделать начальное дробление группы, вам нужно выставить настройку «Степень схожести результатов поиска» в значение «min», а значение «Максимальное число кластерных тестов» выставить в 0 (ноль). В этом случае, запросы будут распределены по кластерам по принципу хотя бы одного любого совпадения с любым URL в выдаче по любому запросу из кластера.
В результате начального дробления образуются такие кластеры, запросы из которых никогда не смогут объединиться с запросами из других кластеров т.к. не имеют с ними ни одного общего совпадения. А те запросы, которые не будут объединены в группы, уже не объединятся ни с какими другими и их можно из последующей перекластеризации исключить.
Перекластеризация
Программа TopSite позволяет делать перекластеризацию сколько угодно раз, если данные уже были собраны. Важно не закрывать программу чтобы не потерять собранные данные. Рекомендуется включить опцию сворачивания в трей и использовать компьютер с автономным питанием на случай отключения света. Возможно, в будущем, будет реализовано сохранение собранных данных на диск.
Что касается результатов перекластеризации, то механизм хранения данных программы позволяет сохранять все изменения и манипуляции включая номера присвоенных кластеров. Всю историю группы вы можете видеть в левом-нижнем углу главного окна программы, под надписью «Дата и время».
Важный момент: собранные при кластеризации данные хранятся с привязкой к конкретной записи даты-времени. Если вы запускаете перекластеризацию, то данные мигрируют в другую запись даты-времени (последнюю). В следующий раз перекластеризацию можно запустить только из последней даты-времени, а в предыдущих записях этот пункт меню становится недоступным.
Ещё один важный момент, связанный с пунктом контекстного меню «Кластер в группу»:
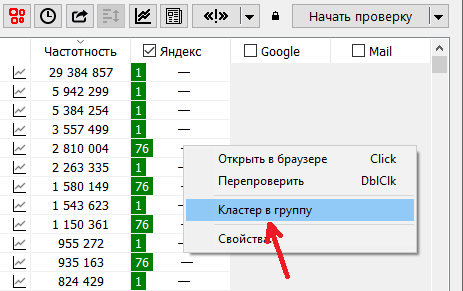
Этот пункт меню позволяет сделать из кластера отдельную группу и перенести в неё все запросы из выбранного кластера. Вместе с кластером, к новой группе присоединяются и часть данных для перекластеризации. Из исходной же группы, запросы этого кластера удаляются. Но перекластеризацию оставшихся всё же можно выполнить. Однако нужно сначала установить флаг сохранения (нажать на кнопку с замком, иначе запуск перекластеризации будет недоступен):
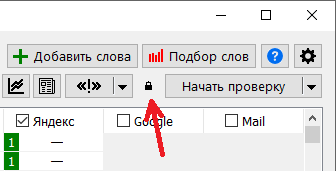
Это сделано чтобы избежать коллизии т.к. перекластеризацию во время работы можно приостановить и затем снова запустить. В этом случае, кнопка сохранения будет серого цвета, что означает, что операция ещё не завершена.
Итак:
Если данные в группе сохранены, то можно начать новую перекластеризацию (при наличии прикреплённых данных);
Если данные не сохранены, то возможно лишь продолжить прерванную перекластеризацию, а для начала новой, данные нужно сначала сохранить (нажать кнопку замка).
При начале новой перекластеризации в списке даты-времени будет создана новая запись и данные для перекластеризации будут перенесены в неё.
Выделенные запросы также можно переносить из группы в группу через буфер обмена. Но в этом случае никакая дополнительная информация кроме запроса и частотности не копируется. Не переносятся и данные для перекластеризации.
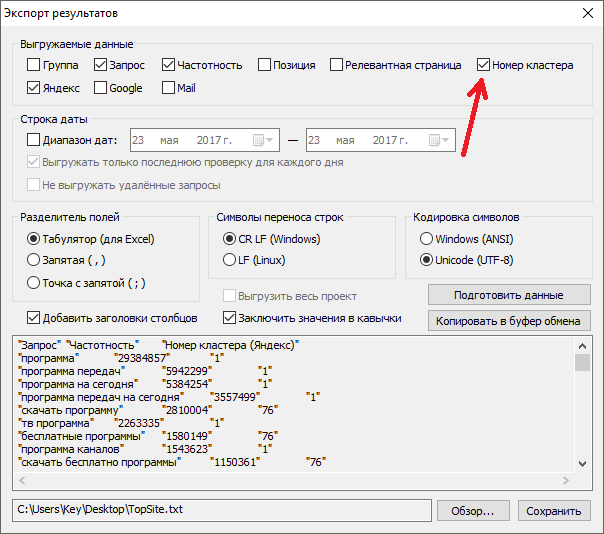
Номера кластеров можно экспортировать через диалог экспорта, например, для вставки и работы с ними в Excel: