Описанный в этой статье алгоритм предназначен для группировки (кластеризации) ключевых слов (запросов) на основе выдачи поисковых систем по этим запросам. Группировка бывает необходима при создании новых интернет-сайтов, а также при реорганизации структуры и оптимизации уже имеющихся веб-сайтов. Она также используется при создании и ведении контекстных рекламных кампаний. Целями данной группировки являются:
- Очистка семантического ядра от неподходящих ключевых слов;
- Группировка ключевых слов для создания структуры сайта или контекстных объявлений;
- Более полное понимание намерений пользователей по неоднозначным поисковым запросам;
- Выделение региональных, коммерческих и других специфических типов поисковых запросов;
- Объединение в одну группу поисковых запросов, сильно отличающихся по написанию, но идентичных по содержанию или намерению пользователя;
- Оценка необходимости разделения похожих поисковых запросов на разные группы для раздельного продвижения из-за высокой конкуренции;
- Другие задачи, решение которых требует объединения ключевых слов в группы, подразумевающие одно и то же намерение пользователя, осуществляющего поиск в поисковой системе по этим ключевым словам.
Отличием описываемого алгоритма от имеющихся на данный момент алгоритмов кластеризации поисковых запросов является использование ТОП-30 результатов поисковой выдачи с присвоением каждому из результатов неодинакового веса, убывающего от 1 к 30 месту по гиперболической функции:
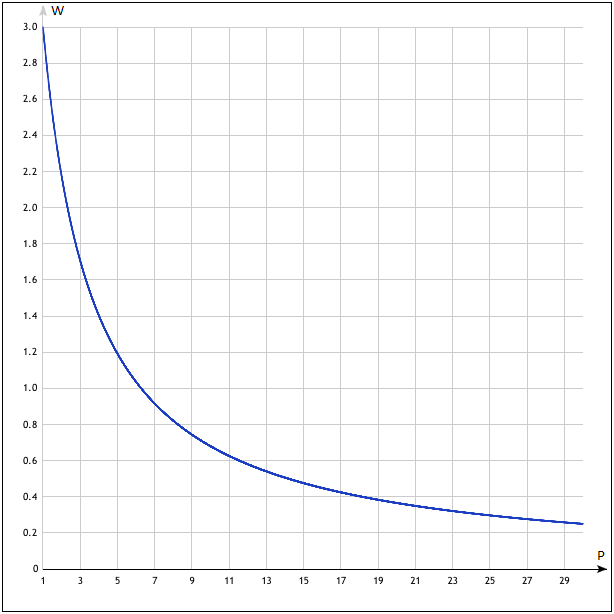
Здесь по оси P отложена позиция результата поисковой выдачи, а по оси W – соответствующий ей вес. Вес первого места составляет 3,0 единицы, 30-го – 0,25 единицы. В вычислениях используются числа с плавающей точкой. График функции предоставлен сайтом yotx.ru.
Выбор данной кривой обусловлен устройством самой поисковой выдачи. Первый результат является самым релевантным (теоретически), а далее релевантность результатов снижается вплоть до нуля (случайного попадания в ТОП при совпадении похожих слов или других факторах). Соответственно, совпадение в результатах поиска по двум разным запросам 1-х мест выдачи значит намного больше, чем совпадение на 20-30-х местах.
Для выявления точных коэффициентов, по которым строится рабочая гипербола, было изучено множество доступных источников и исследований, касающихся поисковой выдачи (её формирование, CTR разных позиций и прочее), а также проведено множество автоматических и ручных тестов кластеризации. Большое спасибо сервису xmlproxy.ru за предоставленные лимиты. И всё ещё нет никакой гарантии, что подобранные коэффициенты являются идеальными во всех случаях. Итоговая формула гиперболы, используемой в данном алгоритме, следующая:
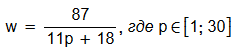
Сравнение отпечатков поисковой выдачи
«Отпечаток выдачи» – условный термин, использующийся в этом описании алгоритма.
Отпечаток выдачи (поискового запроса) – это список (таблица) первых 30 URL-адресов, полученный в результате парсинга результатов поисковой выдачи по заданному поисковому запросу. Каждому из этих URL в отпечатке выдачи присваивается свой вес, соответствующий его позиции в выдаче по этому запросу. Вес рассчитывается по формуле, описанной выше. Число отпечатков выдачи равно количеству запросов в семантическом ядре.
Чтобы сравнить два отпечатка выдачи, нужно найти все совпадающие в них URL-адреса. Для каждого совпавшего URL имеются значения: p1 и p2 – позиции данного URL в первом и втором отпечатке выдачи соответственно, и w1 и w2 – соответствующие им веса. Значения w1 и w2 совпавших URL перемножаются и из полученного значения извлекается квадратный корень. Все полученные результаты суммируются и сравниваются с пороговым значением. Итоговая формула сравнения двух отпечатков выдачи имеет следующий вид:
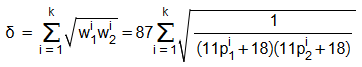
Здесь k – число совпавших URL адресов (если k = 0, то δ = 0). Важно: «i» является верхним индексом, а не возведением в степень!
Полученное значение δ сравнивается с пороговым значением δ0, задаваемым до начала кластеризации. Если δ > δ0, то два ключевых запроса, отпечатки выдачи которых сравнивались, целесообразно объединить в один кластер. δ0∈[0; 21,37124]. Чем больше δ0, тем меньше будет получено групп из 2-х и более запросов.
Функцию (стоящую под знаком суммы), учитывающую совпадение двух URL в зависимости от их позиций, можно представить в виде трёхмерного графика:
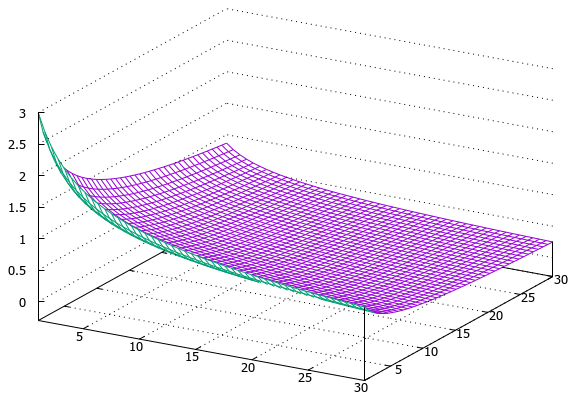
Эта поверхность очень похожа на падающий лист бумаги (конечно, ведь мы же имеем дело с документами :-). Здесь ближайшая к нам координатная плоскость касается листа, вычерчивая ту самую гиперболу, с которой всё начиналось. Аналогично и с левой координатной плоскостью. А точка на этом листе бумаги соответствует значению, полученному в зависимости от весов URL в отпечатках выдачи. За график спасибо сайту grafikus.ru.
Так как для работы алгоритм использует числа с плавающей точкой, то для ускорения вычислений имеет смысл заранее составить таблицу перемножений с извлечением корней. Ячеек в этой таблице всего 30*30 = 900, что не займёт много памяти (читай, вообще не займёт), а повышение скорости будет значительным. В итоге нужно будет найти всего лишь сумму значений из подготовленной таблицы:
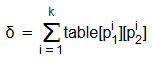
Порядок работы алгоритма
Подготовка к работе алгоритма включает в себя инициализацию описанной выше таблицы, задание порогового значения δ0, а также других параметров, связанных с конкретной реализацией алгоритма (порядок прохода по списку запросов, количество и порядок сравнения запроса с запросами, уже имеющимися в кластере и т.д.).
Для каждого поискового запроса из исследуемого списка запросов необходимо сделать следующее:
- Получить результаты ТОП-30 поисковой выдачи по этому запросу и сформировать отпечаток выдачи.
- Если уже имеются отпечатки выдачи по другим запросам, произвести сравнение текущего отпечатка выдачи с каждым из уже имеющихся отпечатков (в соответствии с параметрами конкретной реализации алгоритма).
- Если найден такой отпечаток выдачи, при сравнении с которым достигнуто (превышено) пороговое значение δ0, то добавить текущий отпечаток в кластер найденного отпечатка. Если такой отпечаток не найден, то добавить отпечаток выдачи в новый пустой кластер и перейти к пункту 5.
- Произвести дальнейшее сравнение на предмет объединения кластеров (в соответствии с параметрами конкретной реализации алгоритма).
- Если ещё остались необработанные запросы, перейти к пункту 1.
© Copyright 2017-05-20.
Алгоритм гиперболической кластеризации.
Автор алгоритма: Двуреченский Павел Александрович, Россия, г. Липецк.
Дата первой публикации алгоритма: 20 мая 2017 года.
Алгоритм используется в программе TopSite.